The TAM Is All of Human Labor
Nov 18, 2025
By: Sean Cai (Costanoa Ventures) and Vedika Jain (Weekend Fund)
Automating Work Is a Verifiability Problem
Everyone’s chasing the AI gold rush. Your feed has the visible stuff: agent demos, benchmark charts, the “did you see that demo?!” hit.
The real rush is upstream - where models learn to work: reinforcement learning environments and the eval stacks that teach them what “good” means.
Every white-collar automation problem is really a verifiability problem. White-collar work is hard to automate not because models can’t write or browse, but because “correct” is nuanced. It blends policies, steps, tools, and taste.
RL only makes progress where there’s a usable reward signal, and those signals are easiest to generate at scale when work is verifiable (i.e. “correct” is computable or at least judged consistently).
RL environments and their evals are the new datasets. They turn messy work into graded work, and graded work into trained capability.
That pipeline - from raw workflows to verifiable tasks inside an environment - is the path “not automatable” to “model-addressable.”
Thanks to Jerry Wu (Halluminate), Parth Patel (HUD), Rob Farlow (Plato), Aengus Lynch (Watertight), Xiangyi Li (Benchflow) and countless stealth founders for contributing to this post.
How We Got Here: From Labeling to Verifiable Work
In the mid-2010s, Scale AI pioneered the third-party data labeling market when most enterprises were relatively unsophisticated buyers. Back then, few companies had in-house machine learning (ML) expertise or applied ML teams, so they outsourced annotation, initially for “hard tech” workloads like images for computer vision for self-driving. Cutting-edge ML remained mostly academic and underpowered for broad commercial use, so early enterprise demand for data was limited and often naïve. Scale’s timing proved prophetic: as soon as model performance became constrained by data, and enough sophisticated enterprise ML teams reified, someone could build a big business supplying it.
That moment came with the transformer revolution (circa 2018–2020) and the rise of foundation models. As models like GPT-3 demonstrated astonishing capabilities from large-scale training, the need for much larger and higher-quality “frontier” data surged. The most sophisticated early buyers were the large AI labs (e.g., OpenAI, DeepMind, and Anthropic) that suddenly needed massive, high-quality datasets and human feedback to push performance. Scale’s rise foreshadowed a new ecosystem of AI data providers serving that hunger, where the bottlenecks shifted from volume to task complexity, horizon length, tool use, and modality coverage.
This set the stage for a shift from one-off annotation to long-horizon training tasks, culminating in reinforcement learning (RL) environments that mimic sophisticated workflows. In short: from drawing boxes around stop signs to building simulated workspaces where agents learn by doing.
In the last three years, models have needed less raw data and more complex long-horizon reasoning data - the kind that encodes enterprise workflows typically locked in experts’ heads. Once data became feedback, labeling became verifiable work - and that opened the door to RL environments.
Why Now: Pretraining Plateaus, Mid/Post-Training Rises
Pretraining is losing its edge (unsupervised/self-supervised learning on raw data like text, web, code, etc.) - great for breadth, weak on planning, tool use, and long-horizon reasoning.
The next step change lives in the mid-training and RL/environment work. Post-training will focus on improving deployment, safety, and alignment - making models not just capable, but trustworthy.
RL environments are the current fixation in some circles, but only a piece of a bigger post-training stack. Elsewhere, the spotlight is on world models and VLMs - ways to make more of the real world modelable. World models/VLMs expand what can be simulated; RL then teaches models how to act inside those worlds and replicate workflows.
The first wave of “pretrain-your-own-vertical model” startups now looks close to foundation-model output with some RAG dressing and an embedding vault. As lab models generalize better, many of those startups couldn’t keep up.
The questions are now pragmatic:
- What infrastructure can we build in the mid/post-training layer to simulate and improve model performance on complex real-world tasks?
- How can model architectures expand across modalities?
We’re not researchers, but Doria’s “the model is the product” frame is a useful deep dive. Our lens as early-stage investors is: who’s building the infrastructure where models actually learn?
At the same time, the know-how for building “good-enough” RL and reasoning agents has diffused. The VC-Twitter “bottom-5% rule” captures it well: once models can outperform the weakest humans in a domain, automation is inevitable. Others frame it as democratized “good-enough RL + reasoning.” The early playbook for building “frontier-quality” data and environments, one locked up in labs, has leaked into startup land. The rise of companies like Mercor and Surge are just the opening act of what’s quietly being unleashed.
When Scale started, buyers were naïve and ML wasn’t ready. Now, both are. Labs became sophisticated, high-velocity buyers of frontier data and feedback, and that sophistication is now spreading to enterprises.
Quietly, the next wave of builders has arrived. Forward-deployed teams like the Forge archetype are assembling small groups of crack MLEs with lab relationships, building custom RL environments, and turning them into automation primitives.
Data Marketplaces 2.0: From Annotation to Training Infrastructure
As the feedback layer became the new frontier, the data layer evolved with it. Companies that once sold labeled examples now sell the entire training loop.
A new breed of data marketplaces has exploded onto the scene, epitomized by Mercor and Surge AI. They earned their stripes supplying high-quality labeling and evals to labs, and are quickly expanding into full training infrastructure.
Take Mercor. Founded in 2022 and already valued at $10B at its latest Series C funding round, it connects top labs with domain experts, doctors, lawyers, coders, to label, adjudicate, and give feedback. In effect, it is a marketplace for skilled raters serving the insatiable need for frontier data. Growth has been meteoric, with several Mercor alumni (Metis, Verita AI) spawning vertical-specific versions of Mercor given Mercor’s trailblazing of market TAM.
Surge AI followed a similar arc. Known for high-quality labeling and evals, it became a core supplier to labs, with persistent rumors about strong profitability and sizable rounds. Details vary by source, but the trajectory is clear.
The pattern: these companies are moving up the stack. From selling data and workers to offering the platform enterprises use to train models, and in some cases reportedly partnering with or reselling RL as a Service.
Even Scale AI, the elder statesman here, has repositioned as pure labeling loses steam. Scale is leaning into enterprise and government contracts and layering training and RLHF on top of its platform. Competition is intense and occasionally litigious; witness Scale’s recent suit against Mercor alleging trade-secret misuse. Buyer concentration is high, and spin-offs are touchy territory.
Labeling has matured and partially commoditized. Raw annotation has blended into data plus training solutions. Companies like Mercor and Surge are edging toward quasi-infrastructure for labs and, increasingly, for enterprises that are getting more sophisticated.
Incubation and roll-up platforms with the ability to hire substantial AI talent have noticed. General Catalyst’s 2023 hospital acquisition signaled a playbook for building in new shells. Jared Kushner and Elad Gil’s brain.co echoes the approach in incubation form. The working thesis: AI-native products ship faster from fresh organizations with tight top-down control than from retrofitted Fortune 500s.
So far, we (Sean) has backed two companies in this space with exactly this formula and expect this to become a major theme this year. For teams following this formula without institutional connections, the question centers around building a wedge in enterprise hyper-spenders so you can find the highest value use cases first.
Meanwhile, everyone will train. When Scale emerged, most enterprises lacked the expertise to buy or curate training data. Today, many do. ML infra is more accessible (see open-source and “openpipe” style tools), data is commoditizing, and RL environments are standardizing. Labs are no longer the sole key holders and are actively productizing. We have it on good authority that multiple major labs are training general-purpose finance models with strong browser use capabilities. Though the industry has long known this, OAI’s contracting of ex-bankers to produce reasoning traces/data for automating finance tasks has brought some of this into public view. Finance today; healthcare, law, and other high-value white collar domains tomorrow.
Enterprise ML becomes sophisticated
A few years ago, Fortune 500s and even tech unicorns were far behind the AI labs. Very few had dedicated ML engineering teams or meaningful data budgets. That picture is changing. Applied teams at companies like Ramp, Airbnb, and others now budget like mini-labs, buying parts of the post-training stack rather than end-to-end tools - especially where workflows tie directly to money (customer support, underwriting, auditing, finance ops, coding).
Cursor’s recent move to train internal models (above) for its own application use cases is a useful signal. For product performance, RL is no longer optional. In 2025, companies like Goldman Sachs in finance, Progressive in insurance, and Ramp and Airbnb in tech created internal AI task forces or research groups. These teams are buying parts of the post-training and deployment stack rather than end-to-end solutions.
Their budgets still trail OpenAI or Anthropic by orders of magnitude, perhaps around 1 percent of a top lab’s spend. The difference is that there are hundreds of these enterprise teams forming, which greatly expands the market for advanced data and training services. Spend is growing in areas tied directly to workflows such as customer service, underwriting, and auditing, not only in generic research.
Anecdotes are stacking up. On Wall Street, AI is drafting financial documents and analyzing data. Goldman Sachs’ CEO has said an AI system is doing 95 percent of the work on some IPO prospectuses. Goldman’s CIO has described a growing arsenal of AI tools and internal sidekicks for employees. In insurance, carriers that long used ML for pricing and claims are now exploring policy RL to handle complex customer interactions and risk assessments.
Enterprise AI teams are also purchasing data and evaluations externally the way labs do. A Fortune 500 insurer might hire a vendor to generate specialized underwriting data. A large bank might fund a simulated environment for an AI that assists with compliance checks. A few years ago, many buyers would not have known how to value or integrate such work. Today, some are quietly running pilots with budgets of 1 to 2 million dollars per contract. As successes roll in, budgets loosen, and enterprise spend on advanced training increases.
The best enterprise AI teams now understand post-training techniques and human feedback loops, and they are allocating trial budgets accordingly. These include companies like Ramp, Cursor, AirBnB, and Coinbase, all of whom have talent pipelines that can somewhat rival labs. The world isn’t sophisticated yet for your typical mom and pop shop to buy a Veris type platform, or consider a CloudCruise type platform as critical devtool infra spend, but many are sophisticated enough to contract services-based approaches and promise ARR conversion if they hit benchmarks.
The New Rails: RL Environments and RLaaS
Over the past couple years, the market has shifted toward dynamic, continuous learning approaches like RL to train AI systems. As Felicis put it, reinforcement learning is “rocket fuel” for the AI platform shift. Instead of relying on static datasets, companies now use simulated environments and feedback loops to teach agents multi-step workflows.The aim is human-like learning; Karpathy has noted that near-term paths may not be “pure RL,” but environments still provide the scaffolding that makes such learning possible.
In RL, an agent improves by interacting with an environment, observing outcomes, and receiving rewards/penalties. Early breakthroughs (AlphaGo, OpenAI’s gaming agents) proved this in structured domains. The frontier is now unstructured knowledge work—coding, processing forms, research - where agents practice using software and the web and get graded on multi-step objectives.
We’ve moved up the value chain: from labeling points to orchestrating interactive training scenarios. Static models can’t adapt once trained; RL-style loops enable continuous improvement.
Open source lowered the floor (OpenAI’s Gym, now Gymnasium, RLlib from Ray, HUD’s environments SDK and Prime Intellect, etc.) for RL experiments: a wider community can build environments and share benchmarks. Now the ceiling is dropping: it’s becoming normal to spin up a training environment for a business process.
Just as cloud computing made it trivial to spin up servers, startups are trying to make it trivial to “spin up a training environment” for any business process. Instead of each company collecting its own data or building bespoke simulators, teams can use platforms that already simulate an Excel-like spreadsheet with formula tasks or an email inbox for an AI secretary to manage. Early companies attempting to platformize this for enterprises include Osmosis and Veris.
A parallel track is RL as a Service (more here in our successor piece). These platforms handle parallel simulation and orchestration at scale. If RL environments are the new “datasets,” RLaaS is the new model-training cloud. Teams plug in an environment, define rewards, and train without building RL infra from scratch. Startups like Applied Compute, Veris, and Osmosis offer managed platforms where an enterprise can upload a process and train a custom agent with feedback loops. These services are often pitched for use cases like back-office finance ops but many are still narrowing in on the best verticals.
New Players: Startups Selling RL Environments & Solutions
In the last one to two years, there has been a boom of startups around this shift. Most are U.S.-based, fresh out of stealth or accelerators, and busy assembling the “AI training” stack. Some are building the environment platforms themselves, others offer forward-deployed solutions (i.e. custom RL projects) for enterprises, and many blur the line between product and consulting.
Functionally, an RL environment includes:
Layer 0 - Orchestration: Spin up and reset thousands of runs at once. Keep them deterministic, cheap, and observable.
Layer 1 - Environment: The world where the agent acts: a browser, an app, or a business system like Salesforce or Epic. It should feel real enough to teach, but stable enough to grade.
Layer 2 - Data: Real or synthetic inputs that look like the real world. The better the distribution match, the more the model’s learning transfers.
Layer 3 - Tasks & Rewards: What the agent is asked to do, and how success is measured. Some tasks have one right answer; others have many.
Layer 4 - Verification: The hardest part: deciding what “correct” means when there are multiple good paths.
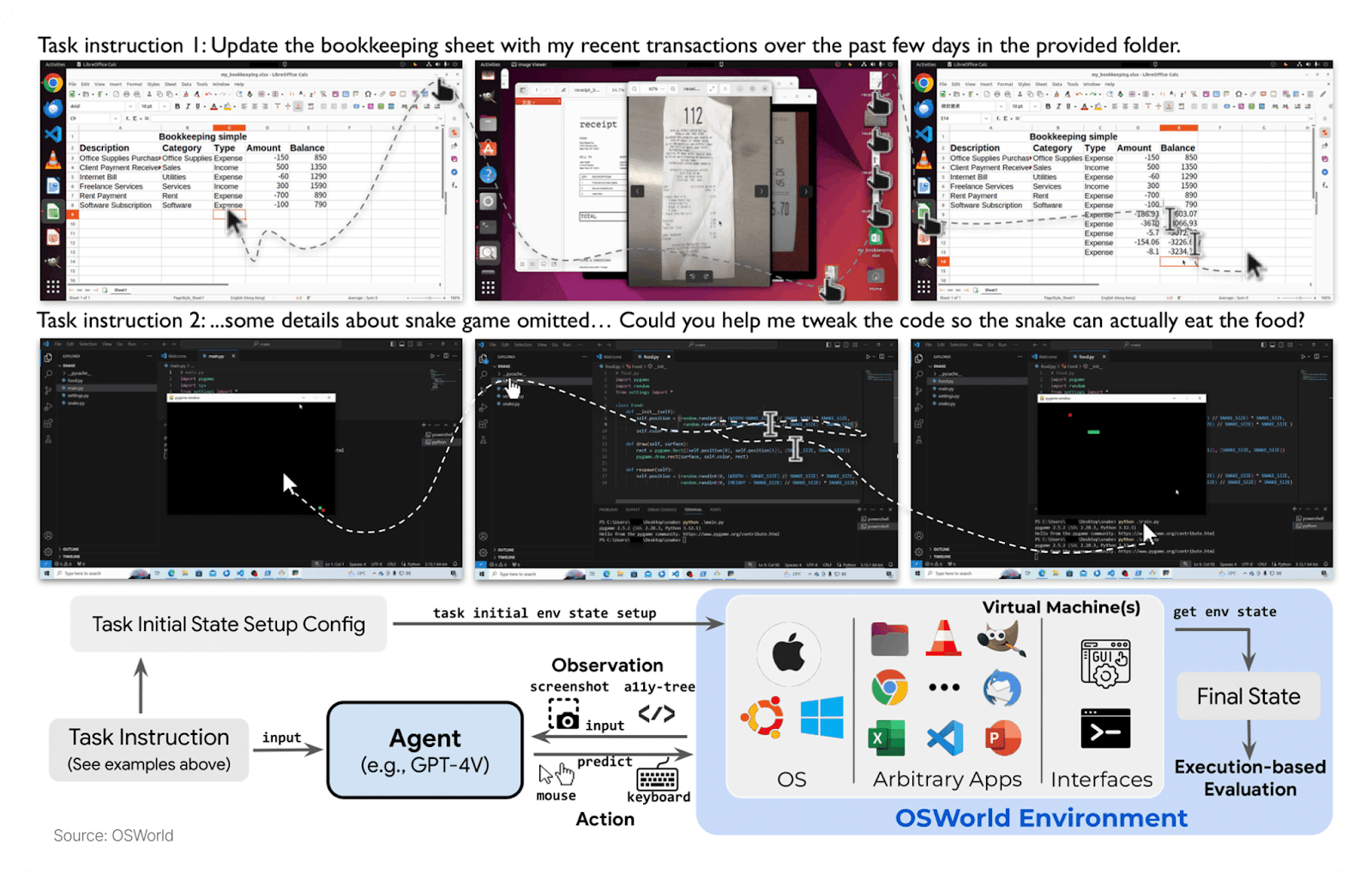
How Environments Get Bought
Go-to-market is deliberately services-heavy: teams lead with an RL environment product and pair it with hands-on implementation to deliver outcomes (the forward-deployed model). One founder put it bluntly: “Half of the RL environment companies are fronts for AI-powered UiPath-on-steroids.” Another: “Sell environments to labs now to earn the right to sell RLaaS and continuous learning to enterprises later.” We think the forward-deployed approach makes sense to access enterprise problems and refine verification. Economically, they look like consultancy or “ML engineering as a service” today, with a path to platform revenue as primitives get reused. They effectively arbitrage the AI talent shortage: enterprises without top-tier ML teams pay for applied implementation; labs outsource evals and net-new data creation to increase velocity.
When selling to labs, most purchase decisions stem from evaluation of data novelty, model improvement capability, and realism. Once an environment or verifier reliably predicts these production KPIs, budgets expand into per-task and per-environment pricing - often one-time purchases where tasks in more “novel” environments (with harder verifiability, multi-domain use cases, complex tool calling, or even multi-environment tasks) are valued higher.
Who buys (and where budget lives)
- Labs: eval/safety leads; discretionary R&D.
- Enterprises: Ops/Risk/Finance or Eng/Product sponsor with an applied-ML lead.
- Application startups: eng/product; small quality/research lines.
Land → expand (typical path)
- Eval pack (land): 4–8 weeks; one deterministic slice. Goal: show eval ↔ prod correlation on a KPI.
- Reward hosting + regression (expand): always-on evals, nightly runs, dashboards, alerts.
- Environment factory (scale): adjacent sub-workflows, shared verifier primitives, orchestration, SLAs
What Winners Look Like
First, a reality check. Realistic environments are needed to push performance today, but the cost of building and maintaining high-fidelity sims is steep. Annualized SaaS is rare so far, which makes sense given demand for environments is barely a year old. Most vendors look like forward-deployed engineering teams more than pure product companies, which is normal in year zero.
Drive COGS down every environment. Winners drive cost per environment down over time. They increase reuse and consistently turn bespoke builds into primitives. They ship each environment faster than the last, push verifier automation up, and prove evaluation-to-production correlation on a real KPI. That compounding loop is the business.
Land with an eval pack; expand to post-training infra. (details in the above “How it’s bought” section).
Price where the value is clear. Today, labs and well-funded enterprises pay roughly $100K–$400K per environment, depending on complexity and the number of in-line tasks. They target domains where frontier models still struggle and tasks have deterministic checks - finance, insurance, and legal multi-step workflows - so ROI is legible.
Build moat from know-how, not just environments. They treat the environment as delivery and the know-how as the moat. They accumulate verifier libraries and grader DSLs, eval-to-prod correlation data tied to KPIs, UI-resilience tooling (state replay, semantic anchors), and trust with labs and top enterprises. They avoid RL theater by showing declining COGS and a reusable stack.
Use commoditization as a wedge, then upsell rewards/monitoring/orchestration. As more miners enter the data mines, simple environments will commoditize. Smart teams will use that as an opening: capture volume and procurement mindshare, then expand up-stack. Once inside a lab’s workflow, a vendor can upsell into reward hosting, safety, and orchestration budgets, just as early cloud providers expanded beyond hosting.
Web2 analogies remain instructive.
- AWS: from commodity hosting to developer infrastructure (databases, analytics, security).
- Stripe: from payments to a broader financial stack (fraud, billing, treasury).
- Twilio: from SMS APIs to the communications budget (voice, video, auth).
If you’re investing in the space, signals to underwrite.
- COGS per environment trending down over time
- Reuse rate of primitives (UI capture, tool adapters, grader DSLs)
- Eval-to-production correlation tied to business KPIs
Data and replay rights retained post-contract
Security, auditability, and traceability posture - Talent flywheel of staff-level MLEs and FDEs with short time-to-impact
And, some red flags to avoid:
- Toy environments that break on SaaS updates
- Heavy human adjudication with drift
- No automation in verifier pipeline
- No path from evaluation budgets to post-training budgets
Adjacencies worth tracking.
A new crop of companies is aggregating reasoning-trace data from games, consumer apps, and browser interactions. These players echo past waves of harvesting latent resources (like spare compute): today, high-fidelity interaction data is the scarce asset fueling verifiers, reward models, and environment synthesis.
Field Notes from Builders
Mindshare vs. training (the hype tax)
“RL environments can absolutely advance capabilities...but they’ve also become a Silicon Valley mind virus. Anyone can build an environment, but will it actually train?” — Parth, HUD
“Environments are a moving target. Models saturate benchmarks fast - what taught a model last quarter won’t teach it next. Durable teams don’t just build once; they ship, measure, and refresh constantly. If your stack can’t evolve with the model, you’re doing RL theater.” — Xiangyi Li, BenchFlow
Evals ≈ Environments (the line has blurred)
“The gap between evals and environments has closed significantly. What used to be commissioned as private evals are now RL environments.” — Parth, HUD
“We started with evals and got pulled into RL. The thread is the same: make the workflow verifiable so the model can learn.” — Jerry, Halluminate
What labs actually buy (quality → speed → scale)
“Labs optimize for three things: quality/realism, how fast you can build, and how many you can build. Hit those, and they’ll scale with you.” — Jerry, Halluminate
“Labs want tens of thousands of tasks, and they need them fast and reliable. The teams that can create new environments quickly...and keep them stable...win the contracts.” — Rob Farlow, Plato
“North star is simple: do models trained in your environment get better at the real task? Eval-to-prodcorrelation is the currency. Labs don’t buy novelty - they buy lift.” — Xiangyi Li, BenchFlow
Verification is the hard part (multiple paths, one grade)
“You can’t validate it from the DOM at all…the database state is the easiest thing…make them have a single deterministic answer or output...which is harder than it sounds.” — Rob Farlow, Plato
“Everyone now knows how to build a basic environment; the challenge is harder tasks that span multiple environments and still grade cleanly.” — Rob Farlow, Plato
“As models move to continuous learning and multi-environment tasks, verification stays the bottleneck...you’ll always need opinionated human data expertise. That’s why RL-env companies don’t go away.” — Rob Farlow, Plato
Data distribution and realism (transfer or bust)
“Training only transfers if your data matches production distributions. The environment has to look and feel like the real apps people use.” — Rob, Plato
“We simulate Epic, generate synthetic data, and keep it realistic...doctors actually using the system...to keep distributions honest.” — Jerry, Halluminate
Tooling gap → Platform plays
“Environments are hard to build—no standardized harness. We’re building the framework + platform—think ‘Vercel for RL environments.’” — Parth, HUD
“Scale isn’t more demos; scale is more environments - with infra that can spin up tens of thousands of sites and reset state on demand.” — Rob, Plato
“As labs and enterprises adopt multiple RL environments -- often from different vendors -- we expect shared protocols to emerge. Interoperability layers like Harbor or PrimeIntellect’s verifier formats will standardize evals, rewards, and simulation control. That was BenchFlow’s founding vision: make environments portable and composable by default.” — Xiangyi Li, BenchFlow
Path from services → platform (RLaaS)
“We just did…simulated the data ourselves…need to integrate that interface so the private equity company will be basically fully self-service. They spin up their browsers whenever they want...going from forward deployed to more self service” — Founder, stealth
“The goal was never to sell just RL environments. It was downstream [redacted industry] automation — being the training leader for [redacted industry] automation.” — Founder, stealth
Ontologies & verticalization (two routes to product)
“We’re trying to go in behind and go direct to the data to build up the ontology automatically … pattern matching to build an environment where those workflows can be coded up.” — Founder, stealth
“We’re going two directions…up to higher-value customers now that we have a track record … and a generalized version for smaller companies.” — Founder, stealth
Alignment & telemetry (don’t overfit the grader)
“We have a vision where we’re going to create environments that look like GDP-Val …the evaluation that OpenAI made to measure Agent’s ability to complete normal remote work tasks. And then we stack that out with evaluations when the model can get hijacked into harmful things and measure the ability of defenses to prevent it.” — Aengus (Watertight AI)
“Capture reasoning traces, watch for reward hacking, and expose telemetry...or you’ll overfit to the grader.” — Parth, HUD
Talent & buildability (code is easy; data is hard)
“Ninety percent of strong full-stack engineers can build environments with the right tooling stack. You’re constrained by data, not code.” — Parth, HUD
“AGI is AI that can train AI … that means getting over the data barrier … most of ML engineering is 80% data engineering.” — Founder, stealth
Unique datasets
“Researchers are interested in us because we give them interesting data that is not like every other browser environment...they want quality of this unique data which we can provide through sourcing the best contractors.” — Founder, stealth
What’s Next
Labs are developing vertical-specific AI agents or models in secrecy. For example, it’s been reported that virtually all the major labs are currently training general-purpose financial agents/models that are adept at tasks like financial analysis, using tools like web browsers to retrieve information. We expect adjacent white-collar domains to follow by market size.
In September 2025, OpenAI announced “Grove”, a program to support very-early founders. It is framed as a talent network and support program (not exactly an accelerator in the traditional sense), it signals OpenAI’s intent to foster companies building on its tech - effectively seeding the product layer that OpenAI itself might not directly build. With mentorship, early model access, and/or credits or small checks, OpenAI can steer founders towards applications like finance, healthcare, etc. and it may prime domain expert teams for acquisitions later, as predicted by Doria.
RL env, human data, and RLaaS startups are starting to raise Series A/Bs and mature (Datacurve, David AI, Prime Intellect, others unannounced). The evolution of these companies, and the initial data vendor/RL env companies, will probably look something like this:
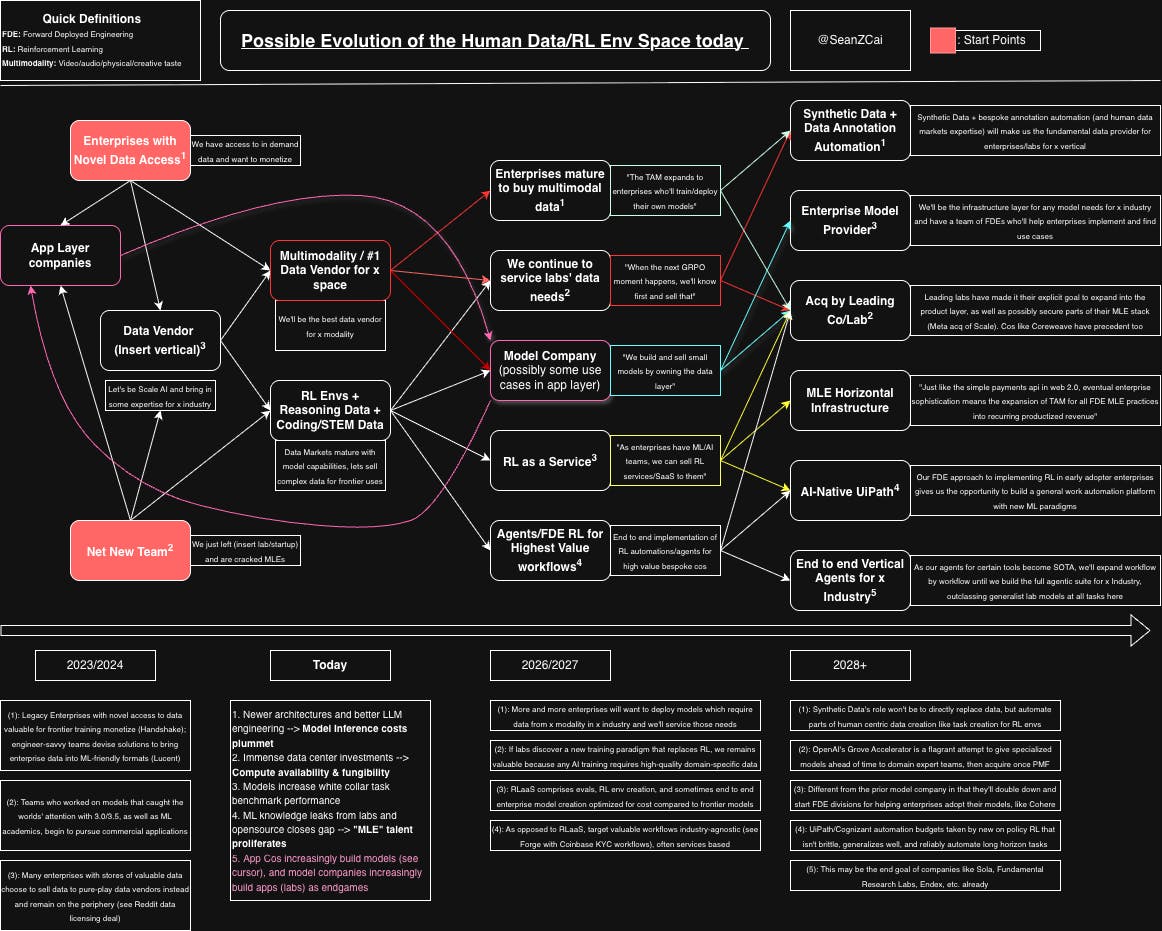
Higher Resolution Image link for above, make sure to open with draw.io.
As can be seen, there are a lot of different moving parts, entry points, and endgames! We generally find RL as a Service to be the endgame most env companies are trending towards as of November 2025.
The TAM is all of human labor. RL is hot today (but look into continuous learning/RL for sparser domains with synthetic data generation next?). As human-data markets mature and enterprises adopt models in production, domain expertise, strong MLE talent, and sharp market selection matter more than ever.
RL as a Service is becoming real as enterprises level up. The vertical approach works when domain expertise is deep. The horizontal approach works (great FDE discovery). The diagonal approach works (raw talent.)
The Landscape at a Glance
Environment Platforms & Verifier/Eval Infra
Mechanize — Env platform (coding)
Primary buyer: Labs, advanced enterprise R&D.
Wedge: High-fidelity “replication training” for long-horizon coding tasks with automatic grading.
Expand: Verifier libraries → reward hosting → monitoring.
Link: mechanize.work
Plato — Browser environments, datasets and tasks
Buyer: Labs, enterprise agent teams.
Wedge: Environments and tasks replicating enterprise scenarios with complex long horizon tasks
Link: plato.so
HUD — Platform to build RL Environments
Buyer: Labs, enterprise, startups.
Wedge: Standardized tooling stack to build RL Environments.
Link: hud.ai
Halluminate — Agent sandboxes + evals (browser/computer use)
Buyer: Labs, applied ML teams.
Wedge: Computer/Tool use environments for financial services knowledge work
Link: halluminate.ai
Idler — Env factory (“Scale for RL envs”)
Buyer: Labs
Wedge: On-demand env generation/orchestration.
Link: idler.ai
Kaizen — One-click RL experimentation
Buyer: Enterprise R&D.
Wedge: Interfaces and infra to spin up continuous learning loops.
Expand: Managed reward services.
Link: n/a
Prime Intellect — RL library/infra
Buyer: Research teams.
Wedge: Low-level RL stack akin to RLlib.
Expand: Env marketplace.
Link: primeintellect.ai
Deeptune — Computer-use environments for multi-step workflows
Primary buyer: Labs, advanced enterprise R&D
Wedge: Domain-specific computer-use environments for Slack and Salesforce
Expand: Reusable verifier packs → RL/RLAIF reward hosting → monitoring and safety for agentic computer-use.
Link: deeptune.com
Vmax — Long-horizon coding and computer-use environments
Primary buyer: Labs
Wedge: Environments targeting extended sequences across coding and desktop/web workflows; emphasis on eval-to-prod correlation.
Expand: Grader DSLs and adapters → reward services → orchestration across training and regression testing.
Link: vmax.ai
Originator AI, Inc — CU/TU RL environments
Primary buyer: Frontier Labs, advanced enterprise R&D
Wedge: Deterministic 'Glass-Box' Environments for Long-Horizon Agentic Workflows
Link: https://originator.inc
Data/Eval Vendors Moving Up-Stack
Surge AI — Frontier data + evals → RL infra
Buyer: Labs; expanding enterprise.
Wedge: High-quality eval frameworks and human feedback.
Expand: Platforms for training/monitoring agents.
Link: surge.ai
Mercor — Expert data marketplace → evals/RL feedback
Buyer: Labs, enterprise ML.
Wedge: Domain experts to define rewards/metrics; expansion into RL loops.
Link: mercor.com
Handshake — Student Jobs Posting platform → Post-training data creation
Buyer: Labs
Wedge: Massive student supply side visibility for lower-intensity white collar educated STEM expertise
Link: handshake ai
Turing — Coding data at scale → mid/post-training services
Buyer: Labs.
Wedge: Human-supervised code tasks; deep vendor relationships.
Expand: Reward modeling, eval tools.
Link: turing.ai
Invisible Technologies — Dataset-as-a-Service
Buyer: Labs, model companies.
Wedge: Scalable workforce + process tooling.
Expand: Eval packs.
Link: invisibletech.ai
Sepal AI — Expert-verified RL envs/benchmarks
Buyer: Labs, enterprise.
Wedge: Contract-based envs; strong adjudication.
Proof: Inter-rater reliability; env reuse.
Link: sepalai.com
Snorkel AI — Programmatic labeling → eval/feedback tooling
Buyer: Enterprise ML.
Wedge: Labeling ops automation; evaluation breadth.
Expand: Post-training feedback integration.
Link: snorkel.ai
Datacurve — Reasoning/code data via bounties
Buyer: Labs, startups. Wedge: Crowdsourced high-skill tasks.
Expand: Eval suites.
Link: datacurve.ai
Verita AI — Multimodal datasets (text/audio/video)
Buyer: Labs, media/creative.
Wedge: Subjective labeling with automation.
Expand: Verifier models for subjective tasks.
Link: verita-ai.com
Prolific — Multimodal panels/data for AI
Buyer: Enterprise research, model teams.
Wedge: Participant quality controls; multimodal tasks.
Link: prolific.com
RLaaS & Forward-Deployed Engineering (FDE) (read more)
Applied Compute — RL platform by ex-OpenAI/Stanford (reported)
Buyer: Labs/enterprises.
Wedge: Scalable RL for dynamic reasoning (public details limited).
Expand: Mid/post-training services.
Link: appliedcompute.com
Watertight AI — Long-horizon misalignment prevention
Buyer: Safety/eval teams.
Wedge: Env + reward designs to reduce reward hacking/drift.
Link: watertightai.com
Luminai — Automation heavy; UiPath-on-steroids angle
Buyer: Ops leaders.
Wedge: Human-in-the-loop automations edging into env-like eval loops.
Expand: Verifiers and monitoring.
Link: luminai.com
Micro1 — AI-assisted coding envs + human-in-the-loop
Buyer: Enterprise eng leaders.
Wedge: Production code tasks with live evaluation.
Expand: Data provider to RL code envs.
Link: micro1.ai
Reasoning-Trace/Interaction Data & Simulated Worlds
General Intuition — Multi-turn reasoning & multimodal data
Buyer: Labs
Wedge: Video/interaction streams to train evaluators/agents
Link: generalintuition.com
Good Start Labs — Game-like tasks/worlds for agents
Buyer: Labs.
Wedge: Rich, verifiable rewards from synthetic worlds.
Link: goodstartlabs.com
4WallAI — Multi-turn reasoning data via games
Buyer: Labs/startups.
Wedge: Naturalistic traces with rewards.
Link: 4wallai.com
LucentHQ — Computer-use interaction data via SDKs in B2B apps
Buyer: Model/eval teams.
Wedge: Real-world UI interaction telemetry.
Link: lucenthq.com
HillClimbing — Math reasoning data
Buyer: Labs.
Wedge: Hard benchmarks for frontier mathematical performance.
Link: hillclimb.ing
Isidor.ai — Finance-focused mid/post-training data & evals
Buyer: Labs; fintech enterprises.
Wedge: Reverse-engineered workflows → high-fidelity reasoning traces.
Link: isidor.ai
If you’re building, let’s talk
We’d love to chat with teams building where models actually learn - especially those with strong MLE expertise and real hiring networks. We’re most excited about new enterprise applications for continuous training and synthetic data that improve in-the-wild model performance.
We invest from pre-seed through Series A (earlier is better), with one goal: maximize the helpfulness-to-check size ratio.
Reach out anytime - sean@costanoa.vc or vedika@weekend.fund.
If these 5000 words weren’t enough, here’s additional reading
- Mary Meeker’s 340 page report on trends in AI (https://www.bondcap.com/reports/tai)
- Redpoint ai64 (https://www.redpoint.com/ai64/)
- Coatue deep dive into whether we’re in an AI bubble (https://drive.google.com/file/d/1Y2CLckBIjfjGClkNikvfOnZ0WyLZhkrT/view)
- Why AI is not a bubble (https://www.derekthompson.org/p/why-ai-is-not-a-bubble)
- Mechanize Blog on RL (https://www.mechanize.work/announcing-mechanize-inc/)
- Vintage Data / Alexander Doria — The Model is the Product (https://vintagedata.org/blog/posts/model-is-the-product)
- Chemistry VC — RL Reigns Supreme (https://www.chemistry.vc/post/rl-reigns-supreme)
- Felicis — Rocket Fuel for AI: Why Reinforcement Learning Is Having Its Moment (https://www.felicis.com/insight/reinforcement-learning)
- More comprehensive list of all notable human data/RL env companies (Notion)
- For the obsessed - A world of automatable domains (Link), A world of verifiable domains (Link), A world of serviceable domains (Link), Post-Training Continuous Learning Papers